
As we saw in part 1 of this series, each program reads stuff from input and writes stuff to output. Whenever it reads strings of characters in the input, these strings are encoded in a certain encoding such as UTF-8. The program must decode these strings into an internal representation. When writing to the output, the program encodes strings from its internal representation to an encoding such as UTF-8.
What this internal representation is is usually not our concern. For example, in Python versions earlier than 3.3, the internal representation is either UCS-2 or UCS-4, depending on how Python was compiled. In Python 3.3 or later, the internal representation is more complicated and described in PEP 393. But these details are rarely of interest; what matters is that a program must be able to communicate with other programs via its input/output, and for this to work properly the programs must agree on an external representation. Whenever you see “appétit” rendered as “appétit” it usually means that two programs did not agree on the encoding of the external representation; for example, that one program sent UTF-8 to its output, and another program read this output as its input, thinking it was ISO-8859-1.
So, you have a Django application that displays images, and the browser shows an image, and under the image it renders the caption of the image, which is “Bon appétit!”. This caption is stored in a CharField or TextField in a model.

Bon appétit!
The string is stored in a file from where it is retrieved by the RDBMS, travelling through Django, the web server, and the web browser, to be finally painted on the screen by the operating system. On this way, it is encoded and decoded several times. The following figure shows more details of this travel of the string:
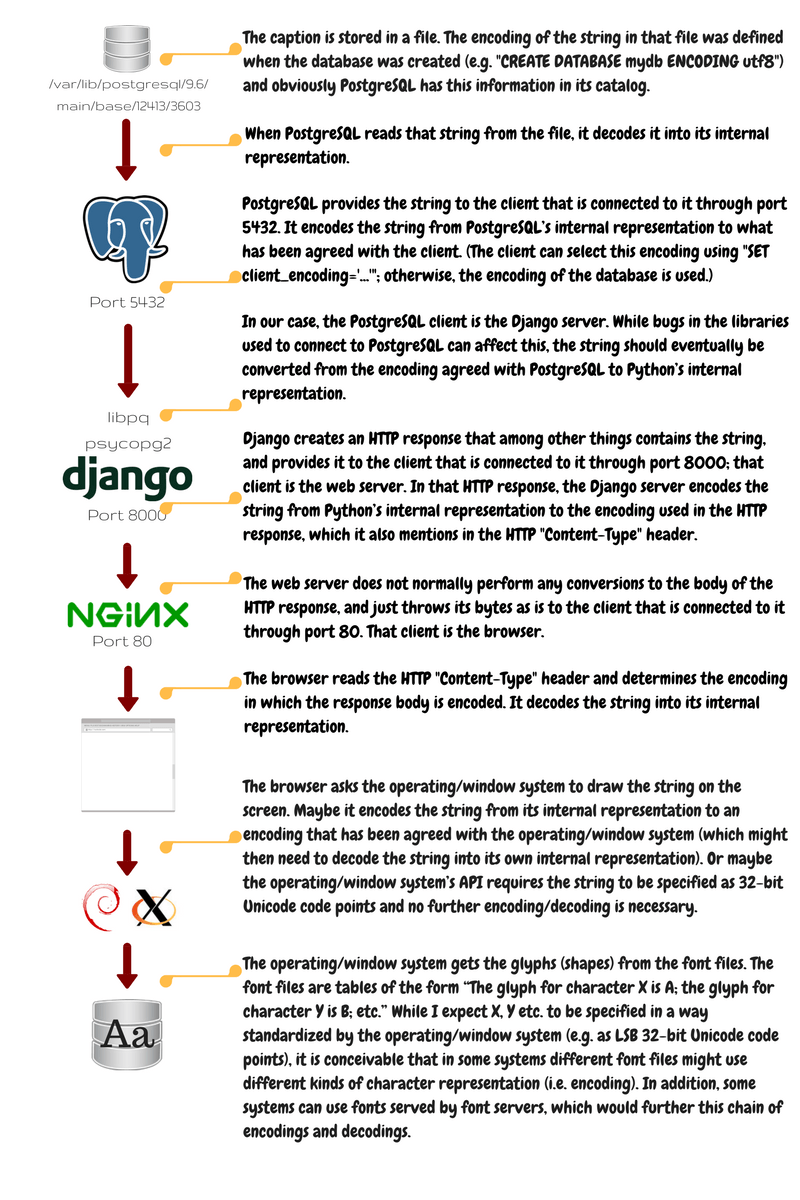
In the end what you must remember is that programs store strings in internal representations and encode/decode them when they communicate with other programs. In the next post we will see what you can do to lessen the probability of some error happening along the way.